AWS S3 이해
AWS 서비스 중 하나인 Amazon S3를 이해해보자.
- Amazon S3 개요
- Amazon S3 기능
- Cross Region Replication
- Transfer Acceleration
Amazon S3 개요
Amazon Simple Storage Service(Amazon S3)는 업계 최고의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스라고 AWS에서 소개하고 있습니다.
모든 규모와 업종의 사용자는 Amazon S3를 사용하여 데이터 레이크, 웹 사이트, 모바일 애플리케이션, 백업 및 복원, 아카이브, 엔터프라이즈 애플리케이션, IoT 디바이스, 빅 데이터 분석 등 다양한 사용 사례에서 원하는 양의 데이터를 저장하고 보호할 수 있습니다.
Amazon S3는 특정 비즈니스, 조직 및 규정 준수 요구 사항에 맞게 데이터에 대한 액세스를 최적화, 구조화 및 구성할 수 있는 관리 기능을 제공합니다.
Amazon S3 기능
1. 스토리지 클래스(Storage Classes)
Amazon S3는 여러 사용 사례에 맞춰 설계된 다양한 스토리지 클래스를 제공합니다.
다음은 S3 콘솔에서 확인할 수 있는 스토리지 클래스입니다.
i. 스토리지 클래스 유형
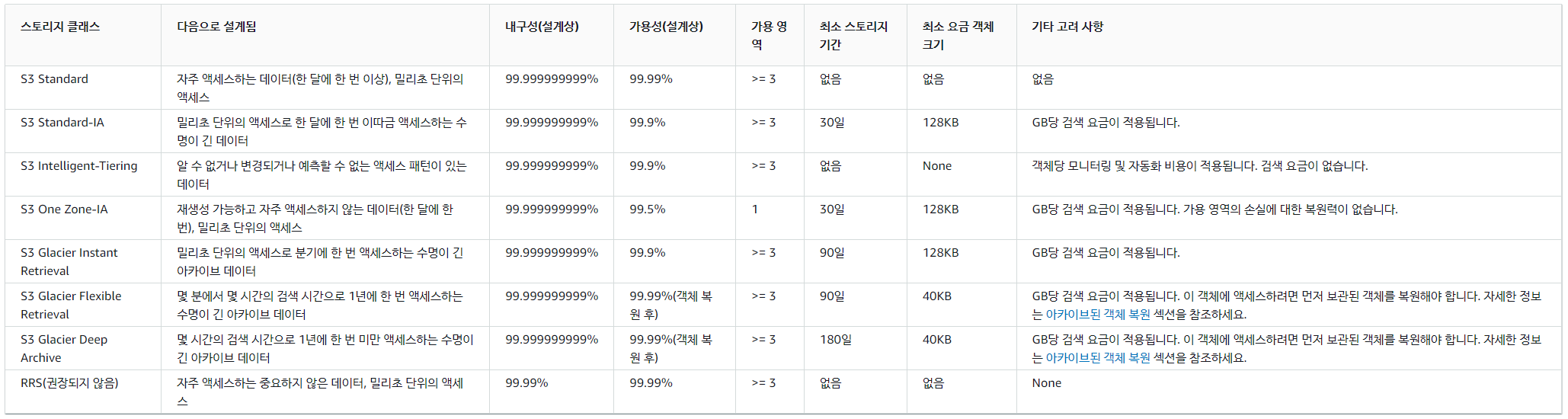
내구성은 법적으로 AWS가 보장하는 수치입니다.
가용 영역은 물리적으로 저장되는 리전을 뜻합니다.
스토리지 클래스는 크게 총 네 가지 클래스로 나눌 수 있습니다.
스탠다드(Standard), 스탠다드-IA(Standard Infrequent Access), 단일 영역-IA, 글래시어(Glacier)가 바로 그것입니다.
- 스탠다드(Standard)
- 가장 일반적인 요금제
- 비싼 스토리지 요금, 저렴한 트래픽 요금
- 자주 액세스하는 데이터에 적합
- 스탠다드-IA(Standard Infrequent Access)
- 스탠다드에 비해서 스토리지 요금은 저렴하나 트래픽 요금은 비싸짐
- 사용 빈도가 다소 낮은 데이터에 적합
- 예) 시간이 지날수록 점점 수요가 줄어드는 뉴스 페이지
- 추후에 기사가 이슈화되어 트래픽이 몰릴 수 있기 때문에 스탠다드-AI에 적합
- 단일 영역-IA(One Zone-IA)
- 스탠다드 데이터는 사동적으로 3곳 이상의 물리적 가용 영역에 백업되지만, 단일 영역-IA는 단일 가용영역에만 저장되기 때문에 재해 등의 이유로 손실될 수 있음
- 스탠다드-IA에 비해서 스토리지 요금이 더 저렴하고 트래픽 요금은 같음
- 사용 빈도가 낮고 중요도가 떨어지는 데이터에 적합
- 예) 트래픽 로그와 같은 많이 발생하지만 없어져도 당장의 큰 영향을 주지 않는 데이터
- Intelligent-Tiering (추가됨)
- 최소 요금 기간이 한 달임
- 주로 예측할 수 없는 워크로드에 사용됨
- 데이터를 가장 비용 효율적인 계층으로 자동 이동하여 스토리지 비용을 최적화 하도록 설계됨
- 약간의 월별 객체 모니터링 및 자동화 요금이 지불됨
- 비동기식으로 액세스할 수 있는 데이터의 경우 S3 Intelligent-Tiering 클래스 내에서 자동 아카이브 기능을 활성화 할 수 있음
- 나중에 IA 계층 또는 Archive 계층의 객체에 액세스하면 자동으로 Frequent Access 계층으로 이동됨
- 객체가 이동될 때는 계층화 요금이 추가로 적용되지 않음
- 글래시어(Glacier)
- Glacier는 빙하를 의미함
- 위 클래스들보다도 더 저렴한 스토리지 요금을 갖지만 훨씬 비싼 트래픽 요금을 가짐
- 데이터 다운로드시에도 몇 시간 단위의 시간이 걸림
- 사용 빈도가 극히 낮은 데이터에 적합
- 예) 거의 열어볼 일은 없지만 장기간 지속적으로 보관해야하는 아카이브용 데이터
- Glacier 클래스에는 Instant Retrieval, Flexible Retrieval, Deep Archive 종류가 있음
- Instant Retrieval : 밀리초 단위의 즉각적인 검색을 이용하여
분기에 한 번 액세스하는 장기 아카이브 데이터용 - Flexible Retrieval : 검색 옵션이 1분부터 12시간까지인
장기 백업 및 아카이브용 - Deep Archive :
일년에 한두 번 액세스하고 12시간 이내에복원할 수 있는 장기 데이터아카이브용
- Instant Retrieval : 밀리초 단위의 즉각적인 검색을 이용하여
- Reduced Redundancy
- Standard와 마찬가지로 자주 액세스되는 객체를 위한 스토리지 클래스
- 중요하지 않은 데이터 보관용
- AWS Docs에서 안내하기를 해당 스토리지는 사용하지 않는 것이 좋으며, Standard가 비용 대비 효과적이라고 함
ii. 스토리지 클래스별 요금(Amazon S3 pricing)
스토리지 클래스 요금은 크게 세 가지 영역으로 나뉩니다.
스토리지 요금은 저장 공간에 따른 요금
요청 및 데이터 검색 요금은 사용자의 요청에 따른 수행 요금
데이터 전송 요금은 송수신 대역폭에 대한 요금
항목별로 하나하나 살펴보자.
요청 단위는 PUT, COPY, POST, LIST 요청(요청 1,000개당)입니다.
기준은 서울 리전입니다.
스토리지 요금
- 스탠다드(Standard)
- 처음 50TB/월 : GB당 0.025 USD
- 다음 450TB/월 : GB당 0.024 USD
- 500TB 초과/월 : GB당 0.023 USD
- 스탠다드-IA(Standard Infrequent Access)
- 모든 스토리지/월 : GB당 0.0138 USD
- 단일 영역-IA(One Zone-IA)
- 모든 스토리지/월 : GB당 0.011 USD
- 글래시어(Glacier)
- Instant Retrieval 모든 스토리지/월 : GB당 0.005 USD
- Flexible Retrieval 모든 스토리지/월 : GB당 0.0045 USD
- Deep Archive 모든 스토리지/월 : GB당 0.002 USD
- 스탠다드(Standard)
요청 및 데이터 검색 요금
- 스탠다드(Standard)
- 0.0045 USD
- 스탠다드-IA(Standard Infrequent Access)
- 0.01 USD
- 단일 영역-IA(One Zone-IA)
- 0.01 USD
- 글래시어(Glacier)
- Instant Retrieval : 0.02 USD
- Flexible Retrieval : 0.03258 USD
- Deep Archive : 0.06 USD
- 스탠다드(Standard)
데이터 전송 요금
데이터 전송 요금은
클래스별로 구분되지 않고 공통적으로 부과됩니다.
요금은 다음과 같습니다.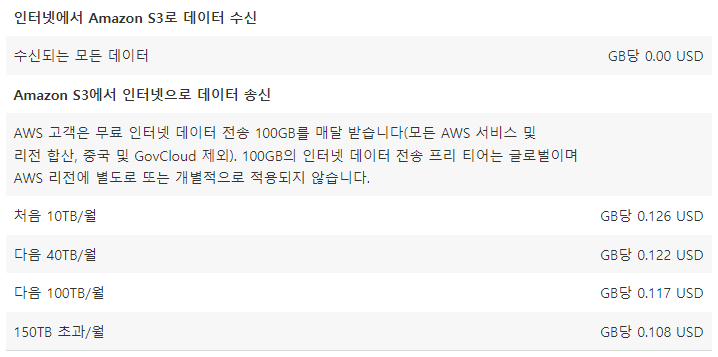
인터넷에서 Amazon S3로 데이터를 수신할 때(Amazon S3에 업로드 할 때)의 요금은 무료입니다.
Amazon S3에서 인터넷으로 데이터를 송신할 때(Amazon S3에서 다운로드 할 때)의 요금은 매달 100GB의 무료 데이터 전송을 사용한 뒤 부과됩니다.
2. Storage Management
Amazon S3에는 비용관리, 규정 요구 사항 충족, 대기 시간 단축, 규정 준수 요구 사항에 맞게 여러 개의 개별 데이터 복제본 저장을 수행할 수 있는 스토리지 관리 기능이 포함되어 있습니다.
i. S3 수명 주기(Lifecycle)
수명 주기 정책을 구성하여 객체를 관리하고 수명 주기 동안 객체를 비용 효율적으로 저장할 수 있습니다.
객체를 다른 S3 스토리지 클래스로 전환하거나 수명이 다한 객체를 만료시킬 수 있습니다.
참고로 S3 Standard-IA와 S3 Standard One-Zone-IA로 전환하는 수명주기 규칙은 최소 S3 Standard 클래스에 30일 이상 보관한 객체만 가능합니다.
Glacier 클래스로의 이동은 제약이 없습니다.
ii. S3 객체 잠금(Object Lock)
고정된 시간 동안 또는 무기한으로 Amazon S3 객체의 삭제 또는 덮어쓰기를 방지할 수 있습니다.
객체 잠금을 사용하면 WORM(write-once-read-many) 스토리지가 필요한 규제 요구 사항을 충족하거나 객체 변경 및 삭제에 대한 보호 계층을 추가하는 데 도움이 됩니다.
iii. S3 복제(Replication)
대기 시간 단축, 규정 준수, 보안 및 기타 사용 사례를 위해 객체, 객체의 각 메타데이터, 객체 태그를 동일하거나 다른 AWS 리전에 있는 하나 이상의 대상 버킷에 복제할 수 있습니다.
iv. S3 배치 작업(Batch Operation)
Amazon S3 콘솔에서 단일 S3 API 요청이나 몇 번의 클릭만으로 수십억 개의 객체를 대규모로 관리할 수 있습니다.
배치 작업(Batch Operations)을 사용하여 수백만 또는 수십억 개의 객체에 대해 복사, AWS Lambda 함수 호출 및 복원 등의 작업을 수행할 수 있습니다.
3. 액세스 관리(Access Management)
Amazon S3는 버킷 및 객체에 대한 액세스 감사 및 관리 기능을 제공합니다.
기본적으로 S3 버킷 및 객체는 프라이빗입니다.
사용자는 자신이 생성한 S3 리소스에만 액세스할 수 있습니다.
특정 사용 사례를 지원하는 세분화된 리소스 권한을 부여하거나 Amazon S3 리소스의 권한을 감사하기 위해 다음 기능을 사용할 수 있습니다.
i. S3 퍼블릭 액세스 차단(Block Public Access)
S3 버킷과 객체에 대한 퍼블릭 액세스를 차단합니다.
기본적으로 퍼블릭 액세스 차단 설정은 계정 및 버킷 레벨에서 할 수 있습니다.
ii. AWS Identity and Access Management(IAM)
AWS 계정용 IAM 사용자를 생성하여 Amazon S3 리소스에 대한 액세스를 관리합니다.
예를 들어 IAM을 Amazon S3와 함께 사용하여 사용자 또는 사용자 그룹이 AWS 계정에 속한 S3 버킷에 대해 보유한 액세스 유형을 제어할 수 있습니다.
iii. 버킷 정책(Bucket Policies)
IAM 기반 정책 언어를 사용하여 S3 버킷과 그 안에 있는 객체에 대한 리소스 기반 권한을 구성합니다.
iv. Amazon S3 액세스 포인트(Amazon S3 Access Points)
Amazon S3의 공유 데이터 집합에 대한 데이터 액세스를 대규모로 관리하기 위해 전용 액세스 정책이 포함된 명명된 네트워크 엔드포인트를 구성합니다.
v. Access Control Lists(ACL)
인증된 사용자에게 개별 버킷 및 객체에 대한 읽기 및 쓰기 권한을 부여합니다.
일반적으로 ACL 대신 액세스 제어를 위해 S3 리소스 기반 정책(버킷 정책 및 액세스 포인트 정책) 또는 IAM 정책을 사용하는 것이 좋습니다.(ACL이 선 적용)
ACL은 리소스 기반 정책과 IAM보다 먼저 적용되는 액세스 제어 메커니즘입니다.
vi. 객체 소유권(Object Ownership)
ACL을 사용 중지하고 버킷의 모든 객체에 대한 소유권을 가져와서 Amazon S3에 저장된 데이터에 대한 액세스 관리를 간소화합니다.
버킷 소유자는 버킷의 모든 객체를 자동으로 소유하고 완전히 제어할 수 있으며 데이터에 대한 액세스 제어는 정책을 기반으로 합니다.
vii. Access Analyzer for S3
S3 버킷 액세스 정책을 평가 및 모니터링하여 정책이 S3 리소스에 대한 의도된 액세스만 제공하는지 확인합니다.
4. Data Processing(데이터 처리)
데이터를 변환하고 워크플로를 트리거하여 다양한 다른 처리 작업을 대규모로 자동화하기 위해 다음 기능을 사용할 수 있습니다.
i. S3 객체 Lambda
자체 코드를 S3 GET 요청에 추가하여 애플리케이션에 데이터가 반환될 때 데이터를 수정 및 처리할 수 있습니다.
행을 필터링하고, 이미지의 크기를 동적으로 조정하고, 기밀 데이터를 편집하는 등의 작업을 수행할 수 있습니다.
ii. 이벤트 알림(Event Notifications)
S3 리소스가 변경되면 Amazon Simple Notification Service(Amazon SNS), Amazon Simple Queue Service(Amazon SQS) 및 AWS Lambda를 사용하는 워크플로를 트리거합니다.
Cross Region Replication
서로 다른 리전에 객체를 복제하여 지연 시간을 최소화 할 수 있는 기능
Transfer Acceleration
거리가 먼 클라이언트와 Amazon S3 버킷 간에 파일을 빠르고, 쉽고, 안전하게 전송할 수 있게 해줍니다.
전 세계적으로 분산된 Amazon CloudFront의 AWS 엣지 로케이션을 활용합니다.
