[AWS-SAA] Examtopics 31~40
SAA Examtopics 31~40번 문제를 풀어보자.
Prob. 31
현재 회사의 레거시 애플리케이션은 단일 인스턴스가 있는 암호화되지 않은 Amazon RDS MySQL 데이터베이스에 의존합니다. 이 데이터베이스의 모든 현재 및 새 데이터는 새로운 규정 준수 표준을 준수하도록 암호화되어야 합니다.
이것은 어떻게 달성될 수 있습니까?
A. 서버 측 암호화가 설정된 Amazon S3 버킷을 생성합니다. 모든 데이터를 Amazon S3로 이동합니다. RDS 인스턴스를 삭제합니다.
B. 암호화가 활성화된 상태에서 RDS Multi-AZ 모드를 활성화합니다. 대기 인스턴스에 대한 페일오버를 수행하여 원래 인스턴스를 삭제합니다.
C. RDS 인스턴스의 스냅샷을 만듭니다. 스냅샷의 암호화된 복사본을 생성합니다. 암호화된 스냅샷에서 RDS 인스턴스를 복원합니다.
D. 암호화가 활성화된 RDS 읽기 복제본을 작성합니다. 읽기 복제본을 마스터로 승격하고 응용프로그램을 새 마스터로 전환합니다. 이전 RDS 인스턴스를 삭제합니다.
해설 : 새로운 규정 준수 표준을 준수하는 암호화 문제 요점. 과거로부터 물려 내려온 것들을 의미하는 애플리케이션으로 다이렉트로 진행중인 RDS를 암호화 시키는 방법은 없음. A 탈락 -> S3에 대한 것으로 DB역할을 못하는 것이라 부적합. B 탈락 -> RDS Multi-AZ 모드를 활성화는 페일오버에 대한 것이라 부적합. C 정답 -> 파일 시스템을 암호화 하는 것으로 평문으로 삽입 후 데이터 전체가 암호화. D 탈락 -> RDS 읽기 복제본은 성능 향상과 Multi-Master에 대한 것이라 부적합.
정답 및 해설 보기
Answer : C
스냅샷을 베이스로 새로 데이터베이스를 만들때만 암호화가 가능.
Prob. 32
마케팅 회사는 Amazon S3 버킷을 사용하여 통계 연구를 위한 CSV 데이터를 저장합니다. Amazon EC2 인스턴스에서 실행되는 애플리케이션이 S3 버킷에 저장된 CSV 데이터를 올바르게 처리하려면 권한이 필요합니다.
EC2 인스턴스의 S3 버킷에 대한 가장 안전한 액세스를 제공하는 단계는 무엇입니까?
A. S3 버킷에 리소스 기반 정책을 연결합니다.
B. S3 버킷에 대한 특정 권한이 있는 응용 프로그램에 대한 IAM 사용자를 생성합니다.
C. 최소 사용 권한(least privilege permissions)이 있는 IAM 역할을 EC2 인스턴스 프로파일에 연결합니다.
D. 인스턴스의 응용 프로그램이 API 호출에 사용할 수 있도록 EC2 인스턴스에 AWS 자격 증명을 직접 저장합니다.
해설 : EC2가 데이터 저장된 S3 버킷을 처리 권한 문제 요점. Amazon S3는 자격 증명 기반 정책 및 리소스 기반 정책(버킷 정책)을 지원. 자격 증명 기반 정책은 IAM 사용자, 그룹 또는 역할에 연결. 리소스 기반 정책은 리소스에 연결. AWS Identity and Access Management(IAM)은 AWS 리소스에 대한 액세스를 안전하게 제어할 수 있는 웹 서비스로 IAM을 사용하면 사용자가 액세스할 수 있는 AWS 리소스를 제어하는 권한을 중앙에서 관리. AWS 계정에 대한 공유 액세스/세분화된 권한/Amazon EC2에서 실행되는 애플리케이션을 위한 보안 AWS 리소스 액세스/멀티 팩터 인증(MFA, OTP)/아이덴티티 페더레이션(다른 곳에 이미 암호가 있는 경우)/보장을 위한 자격 증명 정보/PCI DSS 준수/많은 AWS 서비스와의 통합/최종 일관성 IAM 역할을 할당하는 것이 가장 낫음. A 탈락 -> 리소스 기반 정책(버킷 정책)이라서 하나의 EC2의 정책 설정하는 것은 부적합. B 탈락 -> EC2에서 실행되지 않는 프로그램일 경우 제외로 부적합. C 정답 -> EC2자체에 IAM역할을 주어 적합. D 탈락 -> AWS 자격 증명은 보통 사용자 및 그룹에 적용하며 직접 저장/관리하여 부적합.
정답 및 해설 보기
Answer : C
정책은 자격 증명 또는 리소스에 연결될 때 해당 권한을 정의하는 AWS의 객체.
예를 들어, John이라는 IAM 사용자에게 Amazon EC2 RunInstances 작업을 수행하도록 허용.
누군가 (연결 대상)에 대해 (정책)을 할 수 있/없다의 권한을 부여.
예를 들어, Amazon S3 버킷, Amazon SQS 대기열 및 VPC 엔드포인트 AWS Key Management Service 암호화 키에 리소스 기반 정책을 연결.
연결 대상의 리소스에 (누군)가 (정책)하기 위해 접근하는 것을 허용/거부 한다의 권한을 부여.
다른 옵션들은 CLI등을 통해 내부에 Access Key를 남김.
Prob. 33
Amazon Linux EC2 인스턴스 클러스터에서 기업은 애플리케이션을 실행합니다. 조직은 규정 준수를 위해 모든 애플리케이션 로그 파일을 7년 동안 저장해야 합니다. 로그 파일은 모든 파일에 대한 동시 액세스가 필요한 보고 프로그램에 의해 평가됩니다.
비용 효율성 측면에서 이러한 기준을 가장 잘 충족하는 스토리지 시스템은 무엇입니까?
A. Amazon Elastic Block Store (Amazon EBS)
B. Amazon Elastic File System (Amazon EFS)
C. Amazon EC2 instance store
D. Amazon S3
해설 : 동시 액세스와 비용 효율성 측면 문제 요점. EFS는 Concurrency를 지원해서 동시 접속이 가능하다. S3는 업계 최고 수준의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. 고객은 규모와 업종에 관계없이 원히는 양의 데이터를 저장하고 보호하여 데이터 레이크, 클라우드 네이티브 애플리케이션 및 모바일 앱과 같은 거의 모든 사용 사례를 지원할 수 있습니다. 비용 효율적인 스토리지 클래스와 사용이 쉬운 관리 기능을 통해 비용을 최적화하고, 데이터를 정리하고, 세분화된 액세스 제어를 구성하여 특정 비즈니스, 조직 및 규정 준수 요구 사항을 충족. Write Concurrency를 지원하지 않지만, 지금 상황은 Read이므로 D가 답이라는 말이 있음. 강력한 쓰기 후 읽기(Put작업 후 Get)를 얻는 S3는 많은 문제를 해결. A 탈락 -> EBS는 처음에는 동시성을 만족 못했으나 Multi-attach가 생겨서 동시성은 만족하나 비용 효율적 측면에서 부적합. B 탈락 -> EFS는 동시성을 만족하나 비용 효율적 측면에서 부적합. C 탈락 -> EC2에 직접 저장하는 것은 동시성 측면에서 부적합. D 정답 -> S3에서 로그는 한 번 쓰기 후 읽기에 대한 작업이 많기에 Read 동시성에서는 만족하고 비용 효율적 측면에서도 적합.
정답 및 해설 보기
Answer : D
EFS는 탄력적인 서버리스 파일 스토리지를 제공하는 파일 시스템으로 EC2에 S3를 빠르게 붙이려고 하는 형태임.
Amazon EC2, Amazon ECS 및 AWS Lambda 같은 여러 컴퓨팅 인스턴스가 Amazon EFS 파일 시스템에 동시에 액세스.
스토리지에 대해서만 비용을 지불하고 최소 요금이나 설치 비용은 없음.
대신 공통 데이터 소스가 하나 더 길어지는 대가로 하나의 EFS 파일 시스템이 둘 수 있음.
EC2를 벗어나면 쓸 수 없다?
데이터 레이크 구축(빅 데이터, AI, ML)/중요한 데이터의 백업 및 복원/최저 비용으로 데이터 아카이브/클라우드 네이티브 애플리케이션 실행.
또한 S3는 비용 효율적 측면에서 아주 쌈.
그러나 그것이 우리의 모든 문제가 해결되었다는 것을 의미하지는 않습니다. 보시다시피 비동기 환경에서 S3를 사용할 때 고려해야 할 사항이 있습니다. S3가 애플리케이션이 주어진 버킷에서 쓰고 읽는 방법을 제어 할 수 없기 때문에 S3가 우리를 위해 이러한 문제를 해결할 수 있다고 생각하는 것은 비현실적입니다.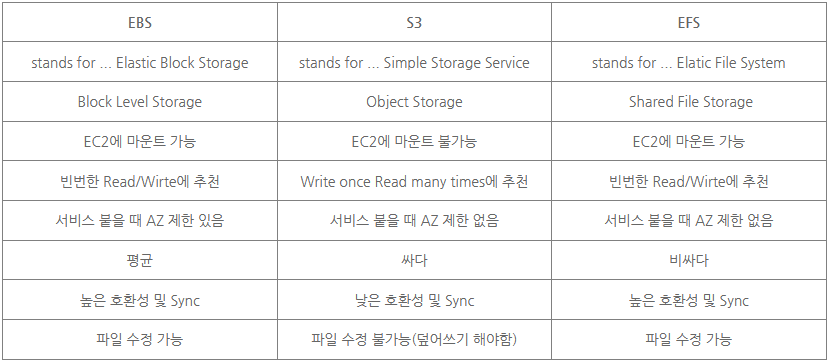
Prob. 34
Amazon EC2 인스턴스 집합에서 기업은 교육 사이트를 제공합니다. 이 회사는 웹에서 수백 개의 교육 비디오를 포함하는 새로운 과정이 일주일 안에 제공되면 엄청난 인기를 얻을 것으로 예측합니다.
솔루션 설계자는 예측된 서버 로드를 최소로 유지하기 위해 무엇을 해야 합니까?
A. Redis용 Amazon ElastiCache에 비디오를 저장합니다. ElastiCache API를 사용하여 웹 서버를 업데이트하여 비디오를 제공합니다.
B. 비디오를 Amazon EFS(Amazon Elastic File System)에 저장합니다. EFS 볼륨을 마운트할 웹 서버의 사용자 데이터 스크립트를 만듭니다.
C. 비디오를 Amazon S3 버킷에 저장합니다. 해당 S3 버킷의 OAI(Origin Access ID)를 사용하여 Amazon CloudFront 배포를 생성합니다. OAI에 대한 Amazon S3 액세스를 제한합니다.
D. 비디오를 Amazon S3 버킷에 저장합니다. AWS 스토리지 게이트웨이인 파일 게이트웨이를 생성하여 S3 버킷에 액세스합니다. 파일 게이트웨이를 마운트할 웹 서버의 사용자 데이터 스크립트를 생성합니다.
해설 : 예측된 서버 로드(외부의 사용자로부터 들어오는 다수의 요청, 도메인 접속 등)를 최소로 유지 문제 요점. 이러한 형태의 경우 대부분 S3와 CloudFront조합이 권고. 사용자 데이터 스크립트에서 AWS CLI를 포함한 AWS API를 사용하는 경우 인스턴스를 시작할 때 인스턴스 프로파일을 사용해야 합니다. 인스턴스 프로필은 사용자 데이터 스크립트에서 API 호출을 실행하는 데 필요한 적절한 AWS 자격 증명을 제공. A 탈락 -> Redis에는 인메모리 데이터에 비디오를 저장하는데에 적합하지 않고 자주 사용되는 쿼리나 데이터를 저장하기에 부적합. B 탈락 -> EFS로 서버 로드를 줄일 수 없음. EFS가 생각보다 빠르지 않고 EBS보다 느리다, 동시성과 탄력성이 좋음 아무튼 부적합. C 정답 -> CloudFront는 뛰어난 성능, 보안 및 개발자 편의를 위해 구축된 콘텐츠 전송 네트워크(CDN) 서비스로 낮은 대기 시간과 높은 전송 속도로 안전하게 콘텐츠 전송하여 적합. D 탈락 -> 온프레미스에서 클라우드로 접근하는 게이트웨이에 대한 솔루션으로 부적합.
정답 및 해설 보기
Answer : C
CloudFront는 Amazon S3 오리진에 인증된 요청을 전송하는 두 가지 방법으로 오리진 액세스 제어(OAC)와 오리진 액세스 ID(OAI)를 제공합니다.
OAC는 모든 AWS 리전/AWS KMS를 사용한 서버 측 암호화/동적 요청(PUT 및 DELETE) 지원하므로 OAC를 사용하는 것이 좋음.
OAI는 3 버킷 콘텐츠에 대한 직접적인 액세스 제한하고, CloudFront를 통해서만 액세스가 가능하도록 OAI(origin access identity)를 설정.
Prob. 35
기업은 3계층 웹 애플리케이션을 온프레미스에서 AWS 클라우드로 전환하기로 선택합니다. 새 데이터베이스는 저장 용량을 동적으로 확장하고 테이블 조인을 수행할 수 있어야 합니다.
이 기준을 충족하는 AWS 서비스는 무엇입니까?
A. Amazon Aurora
B. Amazon RDS for SqlServer
C. Amazon DynamoDB Streams
D. Amazon DynamoDB on-demand
해설 : DB의 동적인 저장 용량 확장과 테이블 조인(RDBMS) 수행 문제 요점. A 정답 -> Aurora는 자동으로 용량이 증감하여 적합. B 탈락 -> RDS는 EBS로 용량을 미리 확보하고 디스크에 한정해서 축소 불가, 확장 가능하는데 수동인 거 같아 부적합. C, D 탈락 -> DynamoDB는 테이블은 오토스케일링은 되지만 조인이 불가능하여 부적합.
정답 및 해설 보기
Answer : A
이것도 디스크에 한정해서 축소 불가, 확장 가능라는데 정확하지 않음. 그리고 엄청 비싸긴 비싸다고 함.
Prob. 36
Amazon EC2 인스턴스 집합에서 기업은 프로덕션 애플리케이션을 실행합니다. 이 프로그램은 Amazon SQS 대기열에서 데이터를 가져와 동시에 메시지를 처리합니다. 메시지 볼륨은 가변적이며 트래픽이 자주 중단됩니다. 이 프로그램은 중단 없이 지속적으로 메시지를 처리해야 합니다.
비용 효율성 측면에서 이러한 기준에 가장 적합한 옵션은 무엇입니까?
A. 필요한 최대 용량을 처리하려면 스팟 인스턴스를 단독으로 사용하십시오.
B. 예약 인스턴스를 단독으로 사용하여 필요한 최대 용량을 처리합니다.
C. 기본 용량으로 예약 인스턴스를 사용하고 추가 용량을 처리하려면 스팟 인스턴스를 사용합니다.
D. 기본 용량에는 예약 인스턴스를 사용하고 추가 용량을 처리하려면 온디맨드 인스턴스를 사용합니다.
해설 : 비용 효율성 측면 기준에서 가장 적합한 문제 요점. 이거나 중단 없이 지속적으로 메시지를 처리 문제 요점. C가 답이라는 주장 - 데이터는 SQS에 쌓이고 있기 때문에, 트래픽이 중단되어도 데이터가 날아갈 일은 없기에 기본 용량으로 예약 인스턴스를 사용하고 추가 용량을 처리하려는 것을 찾으면 됨. 스팟 인스턴스 < 예약 인스턴스 < 온디맨드 < 전용 호스트 A 탈락 -> 스팟 인스턴스는 사용 도중에 반납해야되는 상황이 있어 부적합. B 탈락 -> 상식적으로 필요한 최대 용량을 예약 인스턴스로 만들기 힘들고 그렇게 되면 용량이 남는 경우가 있어 부적합. C 탈락 -> 추가 용량을 처리하려고 제일 싼 스팟 인스턴스를 사용하면 위에서 말했듯이 반납하게 되는 상황이 있어 중단될 가능성이 있다고 생각하여 부적합. D 정답 -> 추가 용량을 처리하려고 온디맨드 인스턴스를 사용하면 비용은 스팟보다 비싸지만 중단되는 일이 없다고 생각하여 적합.
정답 및 해설 보기
Answer : C or D // 내가 생각하기에는 답은 D 인듯
이라고 생각하지만 D라고 생각하는 나는 결국 SQS가 있어도 중단이 발생하는데 요구사항에 중단 없이라는 것이 있기때문에 C가 옳지 않다고 생각하며 만약 중단되어도 상관없으면 C보단 A가 답에 가깝다고 생각함.
Prob. 37
한 스타트업이 자동차에 설치된 사물인터넷(IoT) 센서에서 데이터를 수집하는 애플리케이션을 개발했습니다. Amazon Kinesis Data Firehose를 통해 데이터가 Amazon S3로 전송되고 저장됩니다. 매년 데이터는 수십억 개의 S3 객체를 생성합니다. 매일 아침 비즈니스는 이전 30일 동안의 데이터를 사용하여 일련의 기계 학습(ML) 모델을 재교육합니다. 회사는 1년에 4번, 이전 12개월의 데이터를 사용하여 다른 기계 학습 모델을 분석하고 교육합니다. 데이터는 최대 1년 동안 최소한의 지연으로 액세스할 수 있어야 합니다. 데이터는 1년 후에 아카이브를 위해 보존해야 합니다.
비용 효율성 측면에서 이러한 기준을 가장 잘 충족하는 스토리지 시스템은 무엇입니까?
A. S3 Intelligent-Tiering 스토리지 클래스를 사용합니다. 1년 후 개체를 S3 Glacier Deep Archive로 전환하기 위한 S3 Lifecycle 정책을 만듭니다.
B. S3 Intelligent-Tiering 스토리지 클래스를 사용합니다. 1년 후 개체를 자동으로 S3 Glacier Deep Archive로 이동하도록 S3 Intelligent-Tiering을 구성합니다.
C. S3 Standard-Infrequent Access(S3 Standard-IA) 스토리지 클래스를 사용합니다. 1년 후 개체를 S3 Glacier Deep Archive로 전환하기 위한 S3 Lifecycle 정책을 만듭니다.
D. S3 Standard 스토리지 클래스를 사용합니다. 30일 후 개체를 S3 Standard-Infrequent Access(S3 Standard-IA)로 전환하고 1년 후에는 S3 Glacier Deep Archive로 전환하기 위한 S3 라이프사이클 정책을 생성합니다.
해설 : 비용 효율성 측면 기준에서 충족하는 스토리지 시스템 문제 요점. 내가 알고 있는 Intelligent-Tiering에 대한 특징 S3 Intelligent-Tiering은 위 내용을 이유로 B는 답이 아니라는 말이 있음. S3 Intelligent-Tiering 스토리지 클래스는 비용적으로는 가장 효율적이고 자동으로 이동. A 탈락 -> 1년 후 직접 S3 라이프 사이클 정책을 만드는 것은 부적합. B 탈락 -> 30일 후에 대한 S3 라이프 사이클 정책이 없어서, 예측되는 패턴이 있어서 부적합. C 탈락 -> Standard-IA는 스토리지 요금이 싸고 트래픽 요금이 비싸기 때문에 30일 전에 대한 매일 접근하는데 부적합. D 정답 -> 30일 전/30일 후/1년 후에 대한 적절한 S3 라이프 사이클 정책이 정해졌기 때문에 적합.
정답 및 해설 보기
Answer : D (or B?) // D가 우세알 수 없음, 변경 또는 예측할 수 없는 데이터 패턴과 개체 크기 또는 보존 기간에 관계없이 독립적인 액세스를 위한 이상적인 스토리지 클래스입니다.
하지만 한 유저는 Intelligent-Tiering이 ML/AI 서비스를 위한 스토리지 클래스이기 때문에 B 일 수도 있다고 말함.
그리고 약간의 월별 객체 모니터링 및 자동화 요금이 지불됨.
Prob. 38
비즈니스에는 Amazon S3에 데이터 스토리지가 필요합니다. 규정 준수 요구 사항은 개체가 수정될 때 원래 상태를 유지해야 한다고 규정합니다. 또한 5년 이상 된 데이터는 감사 목적으로 보관해야 합니다.
솔루션 아키텍트가 가장 노력하기 위해 추천해야 하는 것은 무엇입니까?
A. 거버넌스 모드에서 개체 수준 버전 지정 및 S3 개체 잠금 사용
B. 규정 준수 모드에서 개체 수준 버전 지정 및 S3 개체 잠금 사용
C. 개체 수준 버전 지정을 사용합니다. 5년 이상된 데이터를 S3 Glacier Deep Archive로 이동하기 위한 라이프사이클 정책 지원
D. 개체 수준 버전 지정을 사용합니다. 5년 이상 된 데이터를 S3 Standard-Infrequent Access(S3 Standard-IA)로 이동하기 위한 라이프사이클 정책 사용
해설 : 개체가 수정될 때 원래 상태를 유지와 5년 이상 된 데이터는 보관 문제 요점. 보관 모드 - 객체에 대해 다양한 수준의 보호를 적용. 거버넌스 보관 모드 - 특별한 권한이 없는 한 사용자는 객체 버전을 덮어쓰거나 삭제하거나 잠금 설정을 변경할 수 없음. 규정 준수 보관 모드 - 보호된 객체 버전은 AWS 계정의 루트 사용자를 포함한 어떤 사용자도 덮어쓰거나 삭제할 수 없음. S3 객체 잠금을 사용하면 write once, read many(WORM) 모델을 사용하여 객체를 저장. A, B 탈락 -> 거버넌스/규정 준수 모드든 개체 수준 버전 지정 및 S3 개체 잠금 사용을 사용하면 개체를 수정하거나 삭제하지 못하기에 부적합. C 정답 -> 개체 수준 버전 지정은 여러 버전을 관리하고 수정 가능하는데 다시 이전 버전으로 되돌릴 수 있고 5년 이상된 데이터를 글래시어 딥 아카이브에 저장하는 것이 적합. D 탈락 -> 개체 수준 버전 지정은 여러 버전을 관리하고 수정 가능하는데 다시 이전 버전으로 되돌릴 수 있는데 5년 이상된 데이터를 스탠다드-IA(스토리지 쌈/트래픽 비쌈)에 저장하는 것이 부적합.
정답 및 해설 보기
Answer : C
둘 중 한 가지 보관 모드를 객체 잠금에 의해 보호되는 객체 버전에 적용.
대부분의 사용자가 객체를 삭제하지 못하도록 보호하지만, 필요에 따라 일부 사용자에게 보관 설정을 변경하거나 객체를 삭제할 수 있는 권한을 부여.
보관 모드 기간을 생성하기 전에 거버넌스 모드를 사용하여 보관 기간 설정을 테스트 가능.
객체를 잠그면 보관 모드를 변경할 수 없으며 보관 기간을 줄일 수 없음.
고정된 시간 동안 또는 무기한으로 객체의 삭제 또는 덮어쓰기를 방지하는 데 도움.
물론 거버넌스는 권한을 줄 수 있지만 딱히 설명에 없음.
Prob. 39
여러 Amazon EC2 인스턴스는 애플리케이션을 호스팅하는 데 사용됩니다. 이 프로그램은 Amazon SQS 대기열에서 메시지를 읽고 Amazon RDS 데이터베이스에 쓴 다음 대기열에서 제거합니다. RDS 테이블에 중복 항목이 포함되는 경우가 있습니다. SQS 대기열에 중복 메시지가 없습니다.
솔루션 설계자는 메시지가 한 번만 처리되도록 어떻게 보장할 수 있습니까?
A. CreateQueue API 호출을 사용하여 새 큐를 만듭니다.
B. AddPermission API 호출을 사용하여 적절한 권한을 추가하십시오.
C. ReceiveMessage API 호출을 사용하여 적절한 대기 시간을 설정합니다.
D. ChangeMessageVisibility API 호출을 사용하여 가시성 시간 초과를 늘립니다.
해설 : 메시지가 한 번만 처리되도록 보장 문제 요점. 표시 시간 제한은 Amazon SQS가 메시지를 반환할 때 시작됩니다. 이 시간 동안 소비자는 메시지를 처리하고 삭제합니다. A 탈락 -> Amazon SQS의 CreateQueue API 호출하여 새 표준 또는 FIFO 대기열을 생성, 하나 이상의 속성을 전달. B 탈락 -> AWS Lambda의 AddPermission API 호출하여 AWS 서비스, AWS 계정 또는 AWS 조직에 함수를 사용할 권한을 부여함. C 탈락 -> Amazon SQS의 ReceiveMessage API 호출하여 지정된 큐에서 하나 이상의 메시지(최대 10개)를 검색. D 정답 -> Amazon SQS의 ChangeMessageVisibility API 호출하여 대기열에 있는 지정된 메시지의 제한 시간 초과를 새 값으로 변경(기본 30초/최소 0/최대 12시간)으로 최대한 가시성 제한 시간을 늘려야 메시지를 반환할 때 실패하더라도 다시 삭제 작업을 호출해서 표시 시간이 오래 걸리더라도 한 번만 처리 되기에 적함.
정답 및 해설 보기
Answer : D
그러나 메시지를 삭제하기 전에 소비자가 실패하고 표시 시간 제한이 만료되기 전에 시스템에서 해당 메시지에 대한 메시지 삭제 작업을 호출하지 않으면 메시지가 다른 소비자에게 표시되고 메시지가 다시 수신됩니다.
메시지를 한 번만 수신해야 하는 경우, 사용자는 가시성 제한 시간 내에 메시지를 삭제해야 합니다.
함수 수준에서 정책을 적용하거나, 단일 버전 또는 별칭에 대한 액세스를 제한하도록 한정자를 지정.
Prob. 40
한 기업이 리테일(광고) 웹사이트의 전 세계 출시를 발표했습니다. 웹사이트는 Elastic Load Balancer를 통해 라우팅되는 수많은 Amazon EC2 인스턴스에서 호스팅됩니다. 인스턴스는 Auto Scaling 그룹의 여러 가용 영역에 분산됩니다. 회사는 고객이 웹사이트를 보는 장치에 따라 맞춤형 자료를 제공하기를 원합니다.
이러한 요구 사항을 충족하기 위해 솔루션 설계자는 어떤 단계를 함께 수행해야 합니까? (2개를 선택하세요.)
A. 여러 버전의 콘텐츠를 캐시하도록 Amazon CloudFront를 구성합니다.
B. 트래픽을 다른 인스턴스로 전달하도록 네트워크 로드 밸런서에서 호스트 헤더를 구성합니다.
C. User-Agent 헤더를 기반으로 특정 개체를 사용자에게 전송하도록 Lambda@Edge 기능을 구성합니다.
D. AWS Global Accelerator를 구성합니다. 요청을 NLB(네트워크 로드 밸런서)로 전달합니다. 서로 다른 EC2 인스턴스에 대한 호스트 기반 라우팅을 설정하도록 NLB를 구성합니다.
E. AWS Global Accelerator를 구성합니다. 요청을 NLB(네트워크 로드 밸런서)로 전달합니다. 서로 다른 EC2 인스턴스에 대한 경로 기반 라우팅을 설정하도록 NLB를 구성합니다.
해설 : 고객이 웹사이트를 보는 장치에 따라 맞춤형 자료를 제공 문제 요점. AWS Global Accelerator는 AWS 글로벌 네트워크를 사용하여 퍼블릭 애플리케이션의 가용성, 성능, 보안을 개선하는데 유용한 네트워킹 서비스입니다. Application Load Balancer를 사용하면 URL에 기반하여 대상 그룹으로 요청을 전달하는 규칙이 있는 리스너를 생성할 수 있습니다. Classic Load Balancer, Network Load Balancer 및 Gateway Load Balancer 등 다른 로드 밸런서 유형에는 이 기능을 사용할 수 없습니다. 경로 패턴 규칙은 URL의 경로에만 적용되며 URL의 쿼리 파라미터에는 적용되지 않습니다. NLB(네트워크 로드 밸런서)는 L4의 특성을 이용하는 로드밸런서이다. A 정답 -> B 탈락 -> C 정답 -> D 탈락 -> E 탈락 ->
정답 및 해설 보기
Answer : A, C
Global Accelerator는 애플리케이션 엔드포인트로의 고정 진입점 역할을 하는 두 개의 글로벌 정적 공용 IP(예: Application Load Balancer, Network Load Balancer, Amazon Elastic Compute Cloud(EC2) 인스턴스 및 탄력적 IP)를 제공.
여러 도메인, 호스트, 경로 기반의 라우팅 가능.
즉, TCP와 UDP를 사용하는 요청을 받아들여 부하 분산을 실시.CloudFront는 요청 헤더 기반의 콘텐츠 캐싱이 가능함. 이렇게 하면 사용자가 사용하는 디바이스, 최종 사용자의 위치, 최종 사용자가 사용하는 언어 및 다양한 조건에 따라 서로 다른 버전의 콘텐츠를 제공하여 적합.네트워크 로드 밸런서에서 호스트 헤더를 다른 인스턴스로 트래픽을 전달하도록 구성하면 트래픽만 다른 인스턴스로 가는 것이지 맞춤형 자료가 아니라 부적합.Lambda@Edge는 Amazon CloudFront의 기능 중 하나로서 애플리케이션의 사용자에게 더 가까운 위치에서 코드를 실행하여 성능을 개선하고 지연 시간을 단축할 수 있게 함. Lambda@Edge기능을 사용하면 요청을 제출한 디바이스에 대한 정보가 포함된 User-Agent 헤더를 기반으로 사용자에게 다른 객체를 전송하여 적합. 예를 들어 디바이스별로 사용자에게 서로 다른 해상도로 이미지를 보낼 수 있음.호스트 기반 라우팅은 호스트 헤더에 지정된 도메인 이름을 기반으로 들어오는 트래픽을 라우팅하는 Application Load Balancer 규칙을 만들 수 있습니다. 예를 들어, api.example.com에 대한 요청은 하나의 대상 그룹에 보내고 mobile.example.com에 대한 요청은 다른 그룹에 보낼 수 있으며, 다른 모든 요청은 (기본 규칙을 통해) 다른 서버로 보낼 수 있어 ALB에서만 가능 부적합.경로 기반 라우팅을 구현하려면 리스너 규칙을 구성해야 합니다. 요청을 라우팅하려는 경로 패턴에 따라 각 경로 패턴별로 하나의 규칙을 구성으로 ALB에서만 가능 부적합.
- Ref
