[Python] 파이썬
![[Python] 파이썬](/assets/img/algorithm/main.PNG)
알고리즘에 대해 알아보자.
자료형(Python data type)
프로그래밍에 사용되는 숫자, 문자열 등 자료형태의 모든 것, Python의 자료형은 정수, 실수, 문자, 논리형 등의 기본 자료형 형태를 처리한다.
List
List는 계속 수정이 가능하다. (mutable)
리스트 인덱싱과 슬라이싱
문자열과 마찬가지로 Indexing과 Slicing이 가능하다. tuple도 가능!
인덱싱(Indexing, 가리키다)
인덱스 번호를 사용하여 한 요소의 값을 가져온다.
>>> a = [10, 20, 30, 100]
>>> print(a)
[10, 20, 30, 100]
>>> a[0] + a [2] #a[0]는 리스트 a의 첫 번째 요솟값을 의미한다.
40
>>> a[-1] + a[-2] #a[-1]은 리스트 a의 마지막 요솟값을 의미하고, a[-2]는 뒤에서 두번째의 요솟값을 의미한다.
130
인덱스 번호로 리스트 특정 요소의 값을 수정할 수 있다.
>>> a = [10, 20, 30, 100]
>>> a[2] = 300 #[10] = [0], [20] = [1], [30] = [2], [100] = [3]이다.
>>> print(a)
[10, 20, 300, 100]
슬라이싱(Slicing, 잘라내다)
인덱싱이 한 요소의 값을 가져왔다면, 슬라이싱은 인덱스 번호의 0부터 원하는 위치의 요소까지 값을 가져올 수 있다.
변수명[시작(start):끝(stop):간격(step)]
>>> slicing = ['olaf', 'elsa', 'anna', 'krisoff', 'snowgies', 'sven']
>>> slicing[1:5]
['elsa', 'anna', 'krisoff', 'snowgies'] #앞에서 1개의 요소만 제외하는 것과 같다.
>>> slicing[:6]
['olaf', 'elsa', 'anna', 'krisoff', 'snowgies', 'sven'] #앞에서 부터 6개의 요소만 선택하는 것과 같다.
>>> slicing[2:6]
['anna', 'krisoff', 'snowgies', 'sven'] #앞에서 6개의 요소를 선택한 후 선택한 값의 앞에서 2개를 제외하는 것과 같다.
중첩 리스트에서 슬라이싱
>>> slicing = ['olaf', 'snowgies', ['elsa', 'anna'], 'krisoff', 'sven']
>>> slicing[2:5]
[['elsa', 'anna'], 'krisoff', 'sven']
slicing[2:6]에서 a[3] 값은 중첩 리스트인 ['elsa', 'anna']기 때문에 ['elsa', 'anna']부터 a[5] ‘sven’까지의 값이 된다.
리스트 연산
리스트의 연산은 리스트 내의 값이 아닌 ‘리스트’ 자체를 연산한다.
1. + 리스트 더하기
>>> a = [1, 3, 5]
>>> b = [2, 4, 6]
[1, 3, 5, 2, 4, 6]
2. * 리스트 곱하기
>>> a = [3, 6, 9]
>>> a * 2
[3, 6, 9, 3, 6, 9]
3. len() 리스트 길이 구하기
>>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> len(a)
10
리스트 값 삭제
del() 리스트의 특정 값 삭제
del은 Python이 가지고 있는 자체적인 삭제 함수이다.
>>> a = ['hi', 'hello', 'xoxo', 'goodbye']
>>> del a[0]
>>> a
['hello', 'xoxo', 'goodbye']
del() 슬라이싱
>>> a = ['hi', 'hello', 'xoxo', 'goodbye']
>>> del a[3:]
>>> a
['hi', 'hello', 'xoxo'] #a[3]에 해당하는 요소부터 끝 요소까지 삭제된다.
remove(x) 리스트의 요소 제거
remove()는 지정한 위치 값과 같은 요소를 검색 후 나온 처음 값을 삭제한다.
>>> a = ['가', '나', '다', '라', '마', '바', '사']
>>> a.remove('다')
>>> a
['가', '나', '라', '마', '바', '사']
>>> a.remove('아')
#설정한 값이 없을 경우
Traceback (most recent call last):
File "<pyshell#159>", line 1, in <module>
a.remove('아')
ValueError: list.remove(x): x not in list #오류가 발생한다.
pop() 리스트 요소 끄집어내기
pop()는 지정한 위치 값을 삭제하고 삭제한 값을 취득한다.
>>> a = ['가', '나', '다', '라', '마', '바', '사']
>>> a.pop(2) #리스트의 pop(x)번째 요소를 취득 후 삭제한다.
'다'
>>> a
['가', '나', '라', '마', '바', '사']
clear() 리스트 모든 값 삭제
clear()는 리스트 내에 저장 된 모든 요소를 삭제한다.
>>> a = ['가', '나', '다', '라', '마', '바', '사']
>>> a.clear()
>>> a
[]
리스트 함수
유용하다는 함수 몇가지
append, sort, reverse, insert, count, extend
.append - 리스트에 요소 추가
append()는 ‘첨부하다’라는 뜻으로, 리스트의 맨 마지막에 (x)값을 추가하는 함수이다.
>>> a = [1, 2, 3, 4, 5]
>>> a.append(6)
>>> a
[1, 2, 3, 4, 5, 6] #a.append로 '6' 추가
#.sort - 리스트 정렬
.sort()는 리스트의 요소들을 순서대로 정렬해주는 함수이다.
리스트가 정렬된 상태로 '변경'된다.
정렬 기준은 문자열 : 알파벳 → 가나다순, 숫자 : 오름차순(기본값)
리스트에만 사용할 수 있다.
내림차순 정렬은 sort(reverse=True)를 통해 설정한다.
오름차순 정렬은 sort()를 통해 설정한다.
>>> my_list = [1, 4, 5, 2, 3]
>>> my_list.sort()
>>> my_list
[1, 2, 3, 4, 5]
>>> my_list = [1, 4, 5, 2, 3]
>>> print('기본 설정 정렬 : ',my_list)
기본 설정 정렬 : [1, 2, 3, 4, 5]
>>> my_list.sort(reverse=True)
>>> print('True 내림차순 정렬 :',my_list)
True 내림차순 정렬 : [5, 4, 3, 2, 1]
.sorted() - 순서대로 리스트 정렬
기존의 리스트를 원본을 변경하는 것이 아니라 정렬의 새로운 리스트를 반환한다.
정렬 기준은 문자열 : 알파벳 → 가나다순, 숫자 : 오름차순(기본값)
다른 객체에도 사용할 수 있다.
내림차순 정렬은 sorted(reverse=True)를 통해 설정한다.
오름차순 정렬은 sort()를 통해 설정한다.
>>> my_list = [9, 2, 1, 4, 6, 5, 7, 8, 3]
>>> my_list=sorted(my_list)
>>> my_list
[1, 2, 3, 4, 5, 6, 7, 8, 9]
.insert() - 리스트에 요소 삽입
insert(a,b) 리스트의 a번째 위치에 b를 삽입하는 함수이다.
>>> a = [1, 2, 3, 4]
>>> a.insert(4, 5) #a의 4번째 값에 5를 삽입하라는 뜻이다.
>>> a
[1, 2, 3, 4, 5]
.count() - 리스트 내 요소 x의 개수
count(x)는 리스트 안에 x가 몇 개 있는지 검색 후 그 개수를 알려주는 함수이다.
>>> a = [1, 2, 3, 4, 5, 3, 2, 4, 7, 8, 2, 1]
>>> a.count(2) #a 안에 '2'의 개수를 알려준다.
3
.extend() - 리스트 확장
extend(x)의 x값은 ‘리스트’만 올 수 있고 기존 a리스트에 x리스트를 더하게 된다.
>>> a = ['hi']
>>> a.extend(['nice to meet you'])
>>> a
['hi', 'nice to meet you']
Set
Set은 List의 칭구
List와 마찬가지로 여러 타입의 element들을 저장할 수 있다.
요소들이 순서대로 저장되어 있지 않아 indexing이 존재하지 않는다.
순서대로 저장되어 있지 않아 for문에서 읽어들일때 무작위 순서로 나온다.
동일한 값의 요소가 1개 이상 존재할 수 없다.
새로 저장하려는 값이 포함 되어있는 값이라면 새로운 요소가 이 전 요소를 치환한다.
문법
set을 생성하는 법
1. 중괄호 { } 사용
2. set()함수 사용
set = {12, 23, 31} # 변수를 set으로 지정할 때
set2 = set([12, 23, 31]) # set() 함수 사용
set() 함수를 사용해서 set을 만들기 위해서는 list를 parameter로 전달해야 하는데, 일반적으로 list를 set으로 변환하고 싶을때 사용한다.
ex) 중복된 값을 삭제할 때
set1 = {10, 20, 30, 30}
print(set1)
# output
{10, 20, 30}
set2 = set([10, 20, 30, 30])
print(set2)
# output
{10, 20, 30}
Set 관련 함수
add() 요소 추가
my_set = {10, 20, 30}
my_set.add(40)
print(my_set)
# output
{10, 20, 30, 40}
remove() 요소 삭제
my_set = {10, 20, 30}
my_set.remove(10)
print(my_set)
# output
{20, 30}
LookUp in 조건문에 쓰임
set에 어떠한 값이 포함되어 있는지 알아보는 함수
set에서 lookup을 사용하기 위해서는 in, not in 키워드를 같이 사용해야 한다.
my_set = {10, 20, 30}
if 20 in my_set:
print("20 여기 있어!")
# output
20 여기 있어!
my_set = {10, 20, 30}
if 40 not in my_set:
print("여기 40은 없어")
# output
40은 여기 없어
Intersection (교집합)
& 키워드 혹은 intersection 함수를 사용
set1 = {3, 4, 9, 1, 4, 2, 5, 6, 7, 8, 10}
set2 = {5, 6, 7, 8, 9, 10}
print(set1 & set2)
# output
{5, 6, 7, 8, 9, 10}
Union (합집합)
| 키워드 혹은 union 함수를 사용
set1 = {3, 4, 9, 1, 4, 2, 5, 6, 7, 8, 10}
set2 = {5, 6, 7, 8, 9, 10}
# '|' 키워드 사용시
print(set1 | set2)
# 'union' 함수 사용시
print(set1.union(set2))
# output
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
Tuple
파이썬의 자료구조 Tuple
List와 같이 요소들을 저장할때 쓰인다.
Tuple은 한번 선언되면 수정이 불가능하다. (immutable)일반 괄호를 사용한다.
Indexing과 Slicing은 List와 같다.
List와 같이 데이터를 저장할때, List보다 용량이 적다.
수정이 필요없고 간단한 형태의 데이터를 표현할때에는 Tuple을 사용하는 것이 좋다.
문법
tuple을 생성하는 법
일반 괄호 ( ) 사용
my_tuple = (10, 20, 30)
Tuple의 Indexing, Slicing
list와 동일하다.
my_tuple[0], my_tuple[2]
Tuple은 일반적으로 2개에서 5개 사이의 요소들을 저장할때 사용되는데,
특정 데이터를 ad hoc하게 표현하고 싶을때 사용된다.
예를 들어, 다음의 A, B, C, D의 위치 값을 표현할 때
A = (4, 4) B = (5, -2) C = (2, -2) D = (-3, -2) 이러한 데이터들을 표현할때는 tuple을 사용하는게 좋다.
tuple은 주로 list와 함께 사용되는데,
수정이 필요없는 위와 같은 데이터들을 list와 함께 사용할때
coords = [(4, 4), (5, -2), (2, -2), (-3, -2)]
# list의 요소로 tuple 사용
coords = [ [4, 4], [5, -2], [2, -2], [-3, -2] ]
# list로 동일한 데이터 표현
list 보다는 tuple이 더 효과적이다.
Dictionary
한 세트의 데이터를 적절하게 저장하려면 어떻게 해야할까?
my_list = ["고양이", "코리안숏헤어", "노트북", "맥북", "핸드폰", "아이폰"]
list로 저장한다면 이렇게 밖에 저장하지 못할 것이다.
‘고양이’와 ‘코리안숏헤어’를 한 세트로 묶을 수 있는 자료구조가 바로 Dictionary이다.
파이썬의 자료구조 Dictionary
중괄호 { } 를 사용해 dictionary를 선언한다.
key 와 value 의 값으로 이루어져 있고 key값 : value 값이 나온다.
각각의 key : value 들은 comma 로 구분한다.
Key는 String 뿐만이 아니라 숫자도 가능하다.
Key값은 중복될 수 없다.
이미 존재하는 key값이 또 추가 되면 기존의 key값의 요소를 치환한다.
my_dict = { 1 : "one", 1 : "two"}
print(my_dict)
# output
{ 1 : "two" }
문법
my_dict = { "key1" : "value1", "key2" : "value2"}
“고양이” : “코리안숏헤어”, “노트북” : “맥북”, “핸드폰” : “아이폰”
위의 세트는 Dictionary의 형태는 이렇게 적으면 된다.
my_dict = {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰"}
Dictionary에서 요소 읽어들이기
Dictionary에서 element를 읽어 들이는 법은 list와 유사하다.
list는 index값을 사용하는 반면 dictionary는 key값을 사용한다.
예를 들어, 앞서 선언한 my_dict에서 key값인 “고양이”를
읽어 들이고 싶을 때 my_dict["고양이"]를 작성한다.
Dictionary에서 요소 추가하기
my_dict["책"] = "점프 투 파이썬"
print(my_dict)
{"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰", "책" : "점프 투 파이선"}
my_dict[ "newKey" ] = "newValue" 처럼 사용하면 된다.
Dictionary에서 요소 수정하기
요소 수정이 list와 유사하다. 차이점은 index가 아니라 key값을 사용 한다는 점.
my_dict = {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰", "책" : "점프 투 파이선"}
my_dict["핸드폰"] = "아이폰12proMax"
print(my_dict)
# output
{"고양이": "코리안숏헤어", "노트북": "맥북", "핸드폰": "아이폰12proMax"}
처음부터 비어있는 dictionary를 만든 다음 하나 하나씩 추가하는 것도 가능하다.
my_dict = {}
my_dict[Key] = Value
my_dict[Key2] = Value2
print(my_dict)
# output
{ "Key" : "Value", "Key" : "Value2"}
Dictionary에서 요소 삭제하기
요소 삭제 또한 list와 유사하다. del 변수[Key] 차이점은 index가 아니라 key값을 사용 한다는 점.
my_dict = {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰"}
del my_dict["노트북"]
print(my_dict)
# output
{'고양이': '코리안숏헤어', '핸드폰': '아이폰'}
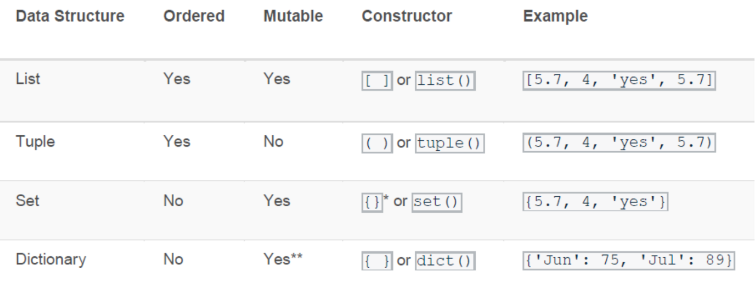
한눈에 보는 자료구조 차이